最近想复习一下python数据处理和机器学习库(pandas/numpy/sklearn/...),于是找了个Kaggle比赛实战。因为以复习为主,心理准备是打到前50%比一半的人好就不算耻辱下播,结果前30%算是超水平发挥了。一方面是之前朋友的建议,一方面是自己也觉得一个月断断续续投入了不少精力,还是有必要总结一下收获。
记录方面分成几个部分,首先是背景——包括比赛介绍和我为什么选择这个比赛,然后是实现思路和工具,最后是对长期目标的反思和规划。当然实际过程中这几个部分不是严格的先后关系,说实话理解这个比赛的需求就有难度,我最开始的实现就是错误的,反过去重新理解要求后才有了正确的实现。
背景
比赛介绍
简单地说,Walmart提供了历史上各超市、各商品的每天销售量,希望预测之后一段时间的每天销售量。比赛提供了三个输入csv文件:
- sales_train_validation.csv / sales_train_evaluation.csv:历史上各超市、各商品的每天销售量,validation是第0-1913天,evaluation是第0-1941天——其实共同部分第0-1913天是一样的,只是id表示法不同,关于两个文件这点之后会吐槽。
- calendar.csv:每天的日期以及是不是节日等额外信息。
- sell_prices.csv:各超市、各商品每天的价格。
需要的输出是一个submission.csv,是各超市、各商品在未来28天(第1942-1969天)的每天销售量。
比赛本身值得吐槽的地方有两个。第一,真正评分用的函数是Walmart自己定义的WRMSSE,是一个形式非常复杂的多层加权时间序列误差,大致讲除了每个商品的原始时间序列外,把每个超市里同一类商品聚合也是一个时间序列——像这样定义了10+层的聚合顺序,WRMSSE则是以最近时间窗口内的销售量为权重,所有原始和聚合时间序列误差的加权和。虽然从业务角度勉强能够理解,但如此复杂的函数导致没有public kernel直接用它或者比较好的proxy作为loss function。即使不考虑比赛者希望用评分函数优化模型,我都有点好奇Walmart内部要如何优化这么复杂的metric。
第二,比赛刚开始只放出了sales_train_validation.csv,public score是基于第1914-1941天的销售量,距离结束前一个月左右(我是这时候参加的)放出了sales_train_evaluation.csv,于是很多人直接提交了正确答案——很长时间排行榜上一大段队伍都是完美的score 0.0,堪称群魔乱舞。除此之外,把数据分成两个id表示法不同的文件放出,也导致了很多没什么意义的工作(处理两遍数据、id转换等)。
软硬件条件
为什么选择这个比赛?一言以蔽之,数据size小。训练模型的硬件方面大致有三种选择,自己的机器,氪金的云服务商(AWS/GCP)和Kaggle的免费kernel服务。不引入分布式的话,机器的内存肯定是越大越好,我自己的笔记本是16GB memory,Kaggle的kernel是16GB memory每次最多连续用6小时,而图像处理类的比赛数据动辄TB起步,M5算是对不想氪金的人比较友好的了。
软件方面倒没什么特别的blocker,记得以前机器学习库还是挺难安装配置的(编译Caffe时还看了不少博客),现在Kaggle的docker也好本地的conda也好,都是开箱即用。
思路和工具
Direct vs Recusive Prediction
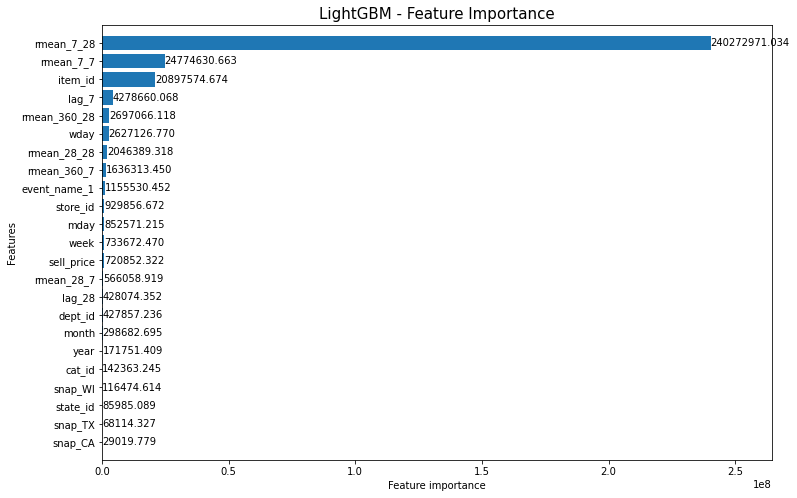
这里direct vs recursive指我们怎样进行多步(28天)的预测,是比model更high level的问题,决定了能选择哪些features。举例来说,几乎所有kernels选择的features里都有每个商品的rolling mean(某商品第X天前,Y天窗口内销售量的平均)。比如下图是LightGBM最后的各feature重要性,其中最重要的rmean_7_28就是7天前28天窗口内的平均销量,从直觉上也可以理解最近一段时间平均值的重要性。
但是当预测未来第28天的时候,之前没有一天的销售量是已知的,要怎么办呢?至少有三种策略:
- 一个模型,放弃rmean_7_28,只用较弱的rmean_28_28。
- 一个模型,把模型输出再作为特征——把预测的天数当作那天的销售量,计算以后的rmean_7_28。
- 分段模型,不同特征。比如分成4个模型,分别预测未来第0-7天、7-14天、14-21天和21-28天,这样第一个model可以用rmean_7_28,第二个model可以用rmean_14_28,以此类推。
其中#1和#3是direct model,#2是recursive model。Pros & Cons还是挺明显的,就不多赘述了。其实这里rmean_7_28也是一种折衷,比如更强大的rmean_0_7会更进一步放大模型误差。
Model
模型方面LightGBM用户压倒性的多。因为总体能用的features数量不多但有大量的categorical features,如果用线性模型那one-hot encoding内存就可以瞬间拉满了,所以tree-based models算是自然的选择。单棵决策树肯定是不够的(至少1000%才行),用ensemble的话无非是基于bagging的random forest和基于boosting的GBDT方法(其实思想有混合,比如LightGBM提供了bagging_fraction参数)。我之前最熟悉的random forest是sklearn,GBDT只接触过XGBoost。稍微调查了一下之后发现,LightGBM和XGBoost算法类似,但是memory用量更少,所以中后期主要是LightGBM了(boosting另一巨头是CatBoost,不过似乎memory用量太大导致没人用)。
我最开始写得prototype是sklearn的random forest,写得时候试图找用sklearn做baseline model的kernels做参考但是完全没有,实际写完就能理解sklearn对比下来实在太难用——同样是接受pandas dataframe,sklearn传categorical features需要人工用LabelEncoder做变换/反变换:
1 | # Before training. |
而LightGBM只要在生成Dataset的时候声明一下:
1 | train_set = lgb.Dataset(train[FEATURES], train[TARGET], categorical_feature = CAT_FEATURES) |
值得一提,我自己过去的印象是Kaggle比赛主要是比谁更能肝更愿意花时间tuning,其实model performance差得比较多的时候,原因很可能是更简单的因素,比如数据量和使用的features。我在本地跑时为了内存和速度只用300天左右的数据,改features也好调参也好public score始终在0.65左右,放到kernel后用了1000天,瞬间到了0.56。
所以比赛最大的难点之一反而是内存管理,能有效压缩内存才能用更多的天数和features训练。个人感觉LightGBM python库的内存处理有点问题,生成Dataset这一步memory用量超过了最后生成的Dataset,从kernel dashboard来看,最后的Dataset在6GB左右,但转换时中间结果能到10GB,直接后果是能用的数据量少(因为超过16GB kernel session就会被断)。当然也可以麻烦点分割数据——比如第4位的解答,就是把每个超市分开,各自训练四个分段模型预测未来四周,可以说是非常有工业界暴力之美了。
反思 & 规划
其实我断断续续地思考过这个问题:data science skills到底算不算需要培养的核心竞争力?我现阶段得出的答案是NO。这么讲倒不是否定data science的价值,而是我比起infra(其实ML frameworks也是一种infra轮子)更喜欢product;而对于产品来说,抛开人造的光环,data science和C++语法同样是工具,是解决问题的「工具」。不懂C++语法是无法动C++ codebase的,但也没必要达到人肉编译器每行代码都是best practice的境界。真正的核心竞争力是解决问题的「能力」以及更meta一层,发现问题的能力,这点其实Google job ladders写得挺好的——工程师的能力,就是在 complexity and ambiguity中产生impact的能力。
我自己学习的原则是"go one layer deeper",比实际使用的技术深入一层。举例来说,使用Spark的话其实只需要懂RDD接口,深入一层理解RDD的fault-tolerance模型可以更好理解应用场景(为什么Google的FlumeJava没有采用Spark这样的内存计算模型?)和怎样高效使用(何时最好persist一下?),但再进一步理解代码实现就没什么短期意义了。所以今后有空我同样也打算粗读一下XGBoost和LightGBM的论文,不管是聊天的谈资还是项目的trade-off都是有价值的。